世界には多くの言語があるが、その大部分は少数言語であり、絶滅の危機に瀕している言語も多い。そのような言語を音声データとして保存する試みが多く行われているが、音声の書き起こしには多くの手間がかかるため、収録したデータの活用が難しい。本研究プロジェクトでは、そのような少数言語の音声データを活用するための技術を開発している。
データを活用する一つの方法は音声検索(Spoken term detection, STD)である。これは、音声を検索キーとして、音声データベース中のキー音声の出現部分を検索する方法である。従来は、音声から抽出したMFCCなどの音響特徴量を、伸縮を許す系列マッチング手法(連続DPマッチングなど)でマッチングして系列間の距離を測り、距離が小さいところでキーとなる単語を検出する。この方法の問題点は、音響特徴量間の距離が、発音内容だけでなく話者の違いにも影響を受ける点である。理想的には、言語的な発音の違いに敏感で、話者に違いには影響を受けない特徴量を使うべきである。このような特徴量として、Posteriorgramが従来用いられている。Posteriorgramは、短時間の音声から音素認識をした時の音素の事後確率である。不特定話者に対する音素認識をすることで、Posteriorgramは話者の違いを吸収して発音の違いのみを表現することができる。しかし、Posteriorgramは言語に依存しており、少数言語に対しては音素認識器を学習することができないため、少数言語の音声検索に従来のPosteriorgramをそのまま利用することはできない。
そこで本研究では、多資源言語(英語、日本語、中国語など)のPosteriorgramを複数組み合わせることによって、そのどれとも異なる少数言語の音声検索精度を向上させる方法を開発した。今回は、対象言語をカクチケル語、多資源言語を英語と日本語として、さまざまな条件での音声検索性能を比較した。その結果、英語と日本語で学習したPosteriorgramを結合して新たな特徴量を作成することで、カクチケル語の検出性能を向上させることができた。
THEME
少数言語の音声データベース活用
- 代表者
- 伊藤 彰則(工学研究科)
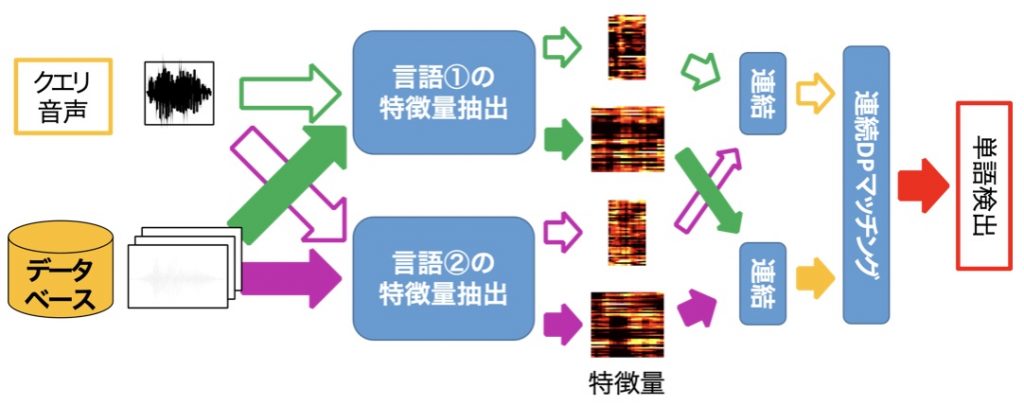
- Fig. 1. Spoken Term Detection using posteriorgrams of multiple languages.
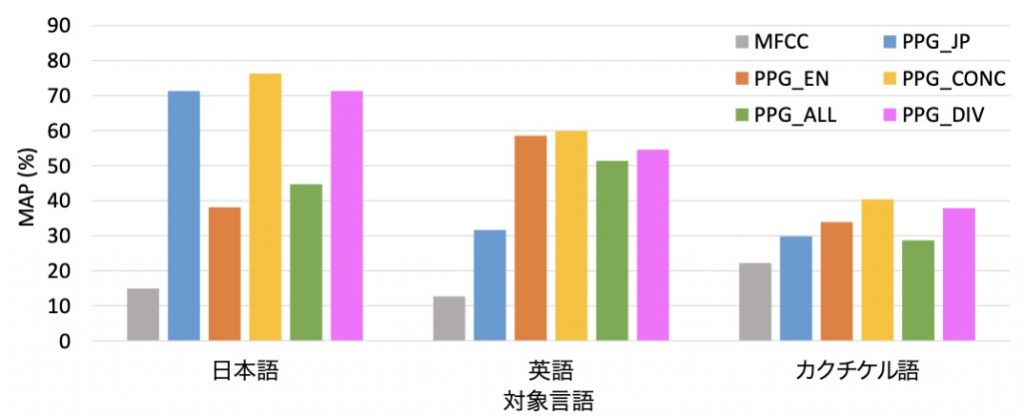
- Fig. 2. STD results for Japanese, English and Kaqchikel speech database. PPG_EN and PPG_JP are posteriorgrams of English and Japanese, respectively. PPG_CONC is the concatenated posteriorgram of English and Japanese. PPG_ALL and PPG_DIV are posteriorgrams trained using both English and Japanese. PPG_CONC showed the best detection performance (Mean Average Precision, MAP) among all the features.